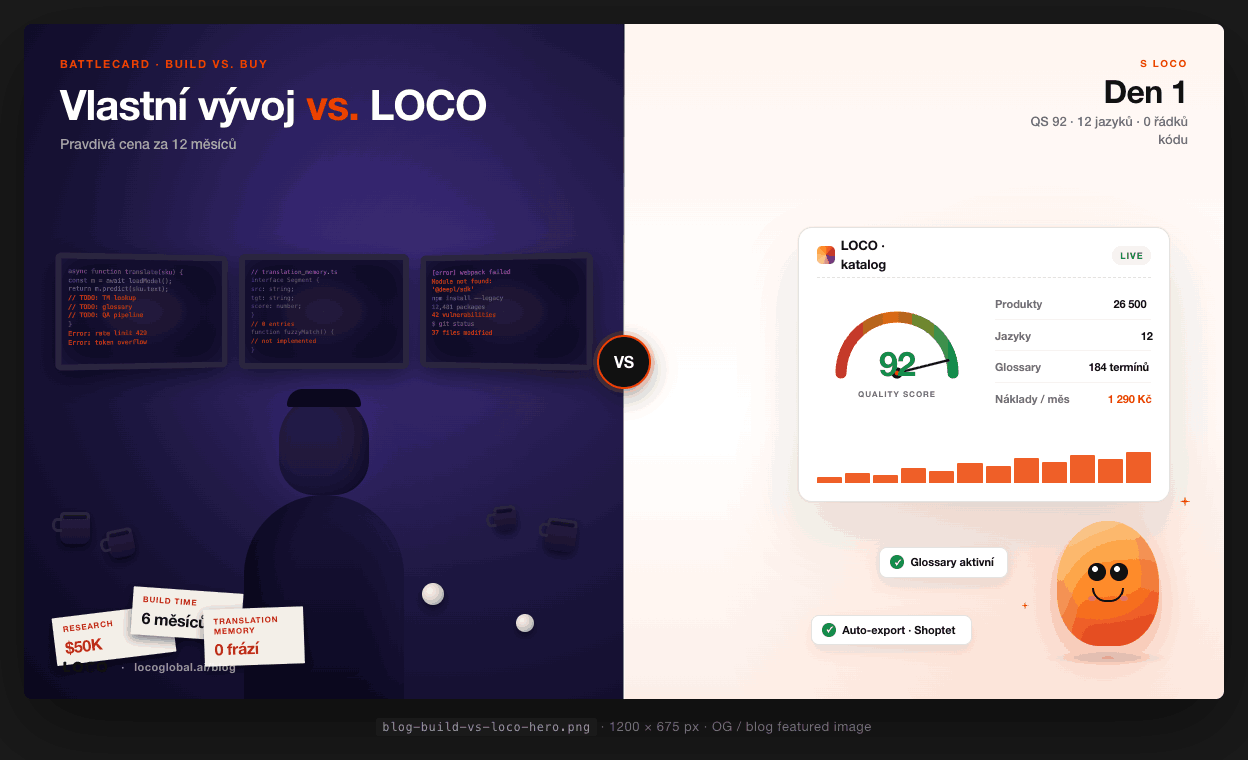
Quality Score 0–100: how to measure localization quality when you don't have time to read every text
A human translator rates quality subjectively. LOCO rates 4 dimensions objectively and tells you which products need attention.

Picture this: 10,000 products translated into 8 languages. That's 80,000 texts. Who's going to read them all?
The old way: nobody. Or a QA team for €8,000 a month.
Today: the LOCO Quality Score.
What the Quality Score is
Every text gets a number from 0 to 100. It's built from 4 dimensions.
1. Grammar and spelling (0–25 points)
Detection of typos, missing diacritics, case errors, punctuation.
2. Clarity and fluency (0–25 points)
An AI model reads the text the way a native speaker would. Misleading phrasing, heavy sentences and awkwardness drop the score.
3. Terminology consistency (0–25 points)
"Hardshell jacket," "hardshell coat," and "hard-shell jacket." Three different terms in one catalog? Minus points.
4. Brand tone and local adaptation (0–25 points)
"Summer Sale" translated as "Summer Promo" vs "Summer Deals." Tone relative to local competitors. Currency, measures, formats.
Reading the score
- 0 to 40: critical errors. Don't publish.
- 41 to 70: understandable but generic. Needs a second pass.
- 71 to 100: natural, consistent, sales-ready. Ready to publish.
Why it changes the game
Before: subjective rating, "kind of OK," based on intuition.
Today: an objective number, concrete identification of weak spots, targeted second pass.
The team doesn't have to read every product. Open the dashboard, sort by Quality Score, focus on the weakest 10 %. Those get a second pass from AI agents. The rest is ready.
Want to see the Quality Score on your catalog? Free audit of 50 products.